در سال های اخیر، تکنولوژی پیشرفت های زیادی در زمینه تولید پردازنده و کارت گرافیک داشته است. یکی از کمپانی های مطرح و به نام، با طراحی معماری پیشرفته و رونمایی از معماری Ampere توانسته است فروش میلیارد دلاری در سراسر دنیا رقم بزند، این کمپانی که تقریبا همگان با نام آن آشنایی دارند، انویدیا است. کمپانی انویدیا با تولید پردازنده های جدید و پردازشگرهای گرافیکی هاپر و همچنین سوپر تراشه هسته ای گریس توانسته تحولی عظیم در دنیای تجهیزات شبکه ایجاد کند و از رقبای خود با اختلاف جلو بیفتد.
ما در این مقاله قصد داریم جدیدترین سوپر تراشه NVIDIA GH200 grace hopper را معرفی کنیم، این سوپر تراشه در سرورها از جمله سرورهای اچ پی قرار گرفته است و عملکردی درخشان با کارایی بالا را موجب گشته است. برای آگاهی از این تکنولوژی خارق العاده تا انتهای این مقاله با ما همراه باشید؛
معرفی سوپر تراشه NVIDIA GH200 Grace Hopper:
کمپانی انویدیا با ارائه جدیدترین سوپرتراشه یعنی GH200 Grace Hopper تحولی عظیم در عصر محاسبات سریع و هوش مصنوعی مولد AI به وجود آورده است این سوپر تراشه از ابتدا برای HPC و AI طراحی و ایجاد شده است. اما قبل از آن که درباره جدیدترین سوپر تراشه NVIDIA صحبت کنیم، می خواهیم پیشینه این کمپانی و چگونگی تولید GH200 Grace Hopper را مورد بررسی قرار دهیم.
کمپانی انویدیا کار خود را با معرفی معماری هاپر و با پردازشگرهای H100 آغاز کرد که این پردازشگرهای گرافیکی از 80 میلیارد ترانزیستور به وجود آمده اند و این میزان تقریبا دو برابر نسل قبلی پردازشگرها یعنی پردازشگرهایی با معماری آمپر (A100) بوده اند. تعداد هسته پردازشگرهای هاپر از 6900 به 16900 ارتقا یافته اند، افزایش تعداد هسته تنسور موجب می گردد محاسبات هوش مصنوعی با قدرت و سرعت بیشتری انجام می شود.
بعد از معرفی معماری هاپر، کمپانی انویدیا ابر تراشه خود یعنی Grace CPU Superchip را روانه بازار کرد که این سوپر تراشه ها از اتصال دو تراشه مجزا به وجود آمده اند و هر تراشه دارای 72 هسته پردازشی است به عبارتی مجموعا دارای 144 هسته می باشد و پهنای باند آن معادل 900 گیگابایت بر ثانیه است.
خاص بودن این سوپر چیپ به معماری آن بر می گردد. گریس سوپر چیپ بر اساس معماری آرم است و برای بررسی جزئیات دقیق تر می توان گفت، Grace Superchip دارای Arm v9 و پلتفرم neoverse N2 است که نسبت به پلتفرم های قدیمی 40 درصد عملکرد بیشتر و بهتری دارد. حال که تا حدی با تراشه های انویدیا آشنا شدید، می خواهیم به طور اختصاصی به بررسی سوپر تراشه NVIDIA GH200 grace hopper بپردازیم؛
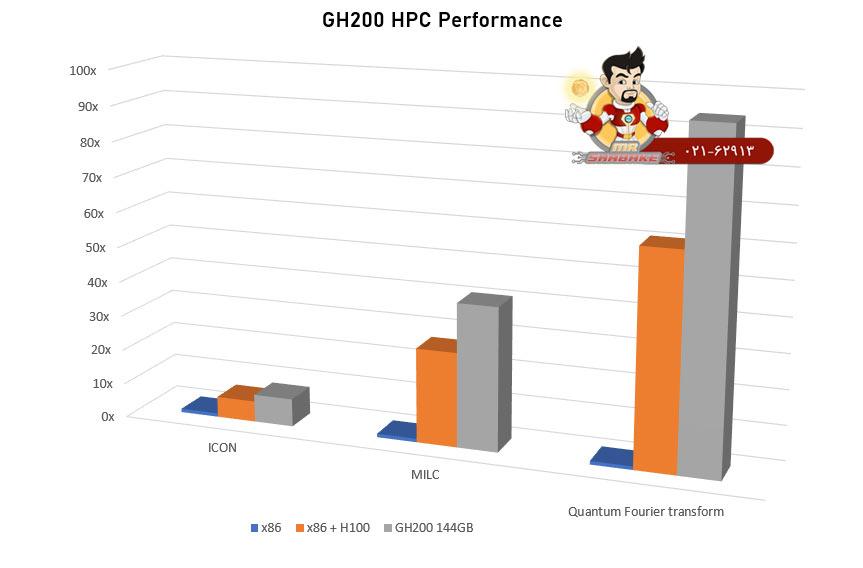
سوپر تراشه NVIDIA GH200 Grace Hopper یک پردازنده پیشرفتکننده است که از ابتدا برای برنامههای کاربردی هوش مصنوعی در مقیاس عظیم و محاسباتی با کارایی بالا (HPC) طراحی شده است. این سوپرتراشه تا 10 برابر عملکرد بالاتری را برای برنامه های کاربردی با مقیاس ترابایت داده ارائه می دهد و دانشمندان و محققان را قادر می سازد تا به راه حل های بی سابقه ای برای پیچیده ترین مشکلات جهان دست یابند.
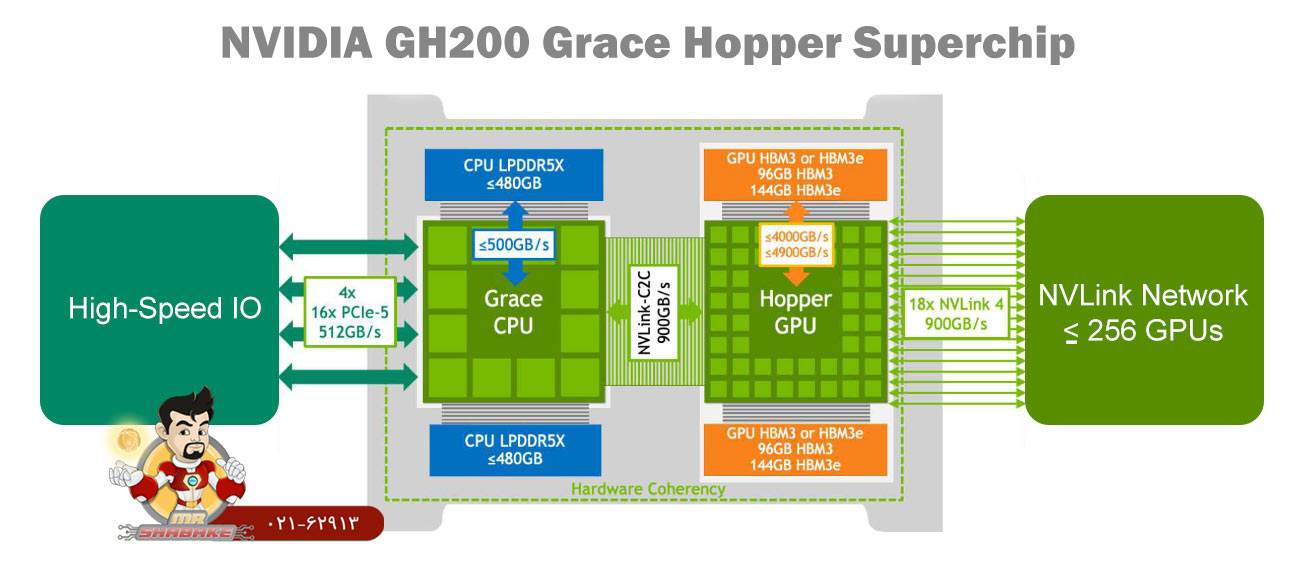
سوپرتراشه NVIDIA GH200 Grace Hopper معماریهای NVIDIA Grace™ و Hopper™ را با هم ترکیب میکند تا یک مدل حافظه منسجم CPU+GPU را برای برنامههای شتابدهنده هوش مصنوعی و HPC ارائه دهد.
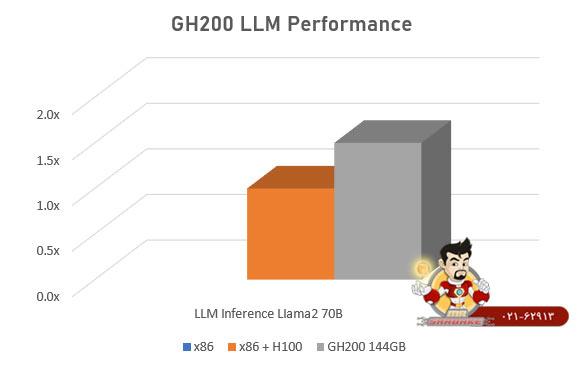
این سوپرتراشه با ارائه پهنای باند 900 گیگابایت بر ثانیه، 7 برابر سریعتر از PCIe Gen5 است و با حافظه گرافیکی HBM3 و HBM3e، محاسبات سریع و هوش مصنوعی تولیدی را سوپرشارژ می کند. GH200 همه استک ها و پلتفرم های نرم افزار NVIDIA از جمله NVIDIA AI Enterprise، HPC SDK و Omniverse™ را اجرا می کند و با آن ها سازگار است.
سوپرتراشه Dual GH200 Grace Hopper به طور کامل دو سوپرتراشه GH200 را با فناوری NVLink به هم متصل می کند و تا 3.5 برابر بیشتر از ظرفیت حافظه GPU و 3 برابر پهنای باند بیشتر از H100 را در یک سرور واحد ارائه می دهد هدف از ارائه این محصول بهبود کاربری در AI و HPC در مقیاس بزرگ در مقایسه با نسل های قبلی است.
این محصول با ارائه پهنای باند بالا و ارائه حافظه منسجم و همچنین پشتیبانی از سیستم سوئیچ NVIDIA NVLink در محصولاتی از جمله سرور اچ پی DL384 G12 و سرور اچ پی DL380a G12 با قابلیت ارائه هوش مصنوعی به کار رفته است.
NVIDIA GH200 NVL2 چیست:
NVIDIA GH200 NVL2 از اتصال دو سوپرتراشه GH200 و NVLink ایجاد شده است و تا 288 گیگابایت حافظه، پهنای باند حافظه 10 ترابایت بر ثانیه (TB/s) و حافظه سریع 1.2 ترابایت ارائه می دهد. GH200 NVL2 تا 3.5 برابر ظرفیت حافظه بیشتر از GPU و 3 برابر پهنای باند بیشتر از NVIDIA H100 Tensor Core GPU در یک سرور واحد برای بارهای کاری محاسباتی و فشرده ارائه می دهد.
ویژگی های NVIDIA GH200 Grace Hopper:
این پلتفرم به عنوان یک پلتفرم همه کاره در محاسبات جهانی محسوب می شود و دارای ویژگی های شگفت انگیزی است که آن ها را توضیح خواهیم داد:
- دارای معماری پیشگامانه NVIDIA Grace Hopper
- ارائه عملکرد گرافیکی بالا همراه با تطبیق NVIDIA Hopper و NVIDIA Grace
- دارای پردازنده در یک سوپرتراشه واحد همراه با پهنای باند بالا و حافظه منسجم است
- NVIDIA NVLink-C2C یک حافظه منسجم، با پهنای باند بالا و تاخیر کم است
- ارائه پهنای باند 900 گیگابایت بر ثانیه است
- حافظه در هر سوپرتراشه GH200 Grace Hopper، به 7 برابر GPU بیشتر دسترسی مستقیم دارد
- دارای سیستم سوئیچ که تمام رشتههای GPU را به حداکثر 256 GPU متصل به NVLink اجرا می کند
- توانایی دسترسی به 144 ترابایت حافظه در پهنای باند بالا است
- NVIDIA Grace دارای CPU با تعداد 72 هسته است
- دارای پردازنده گرافیکی NVIDIA H100 Tensor Core است
- دارای LPDDR5X با حداکثر 480 گیگابایت است
- قابلیت پشتیبانی از HBM3 با اندازه 96 گیگابایت و HBM3e با اندازه 144 گیگابایت است
- دسترسی سریع به حافظه تا 624 گیگابایت است
- دارای حافظه منسجم NVLink-C2C: 900 گیگابایت بر ثانیه است
| Feature Description |
|---|
| Grace CPU cores (number) Up to 72 cores |
| CPU LPDDR5X bandwidth (GB/s) Up to 500GB/s |
| GPU HBM bandwidth (GB/s) 4TB/s HBM3 |
| HBM3e:4.9TB/s |
| NVLink-C2C bandwidth (GB/s) 900GB/s total, 450GB/s per direction |
| CPU LPDDR5X capacity (GB) Up to 480GB |
| GPU HBM capacity (GB) 96GB HBM3 |
| 144GB:HBM3e |
| PCIe Gen 5 Lanes 64x |
CPU Grace چه کارایی دارد:
CPU NVIDIA Grace می تواند عملکردی 2 برابر در هر وات معمولی ارائه می دهد، این پردازنده یک پلتفرم x86-64 است و سریعترین CPU مرکز داده با معماری Arm® در جهان می باشد. سی پی یو گریس، برای عملکرد تک رشته ای بالا، پهنای باند و حافظه بالا طراحی شده است. این پردازنده دارای 72 هسته Neoverse V2 Armv9 با حافظه LPDDR5X معادل 480 گیگابایت است که قابلیت ECC آن موجب تعادل بهینه پهنای باند، بهره وری انرژی، ظرفبت، افزایش 53 درصدی پهنای باند و هزینه در مقایسه با طراحی هشت کاناله DDR5 را ارائه می دهد.
عملکرد و سرعت در پردازنده گرافیکی Hopper H100:
GPU H100 Tensor Core نسل نهم پردازنده گرافیکی مرکز داده انویدیا است و یک جهش عملکرد مرتبه ای برای هوش مصنوعی و HPC در مقایسه با نسل قبلی پردازنده گرافیکی NVIDIA A100 Tensor Core ارائه می دهد. NVIDIA H100 بر اساس معماری جدید Hopper GPU دارای چندین نوآوری است:
- هسته های تانسور نسل چهارم جدید محاسبات ماتریسی را در مقیاس وسیع تری از وظایف هوش مصنوعی و HPC انجام می دهند
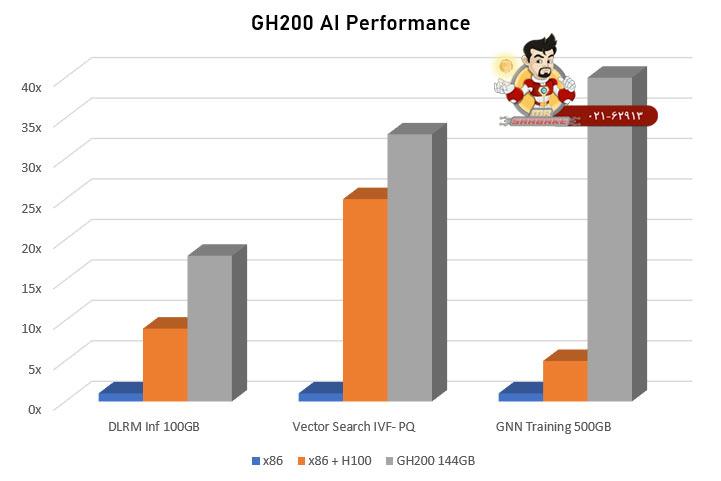
- موتور Transformer جدید H100 را قادر می سازد تا 9 برابر سریع تر آموزش هوش مصنوعی را ارائه دهند و نتیجه گیری از هوش مصنوعی را تا 30 برابر سریع تر در مقایسه با های قبلی ارائه دهند.
- دارای نمونه هایی برای به حداکثر رساندن کیفیت خدمات QoS در حجم کاری کوچک فراهم می سازد.
- دارای قدرت حافظه منسجم است
- با داشتن حافظه NVLink-C2C موجب افزایش بهره وری، توسعه و عملکرد می شود.
پشتیبانی کامل از پلتفرم انویدیا توسط سوپر تراشه GH200 Grace Hopper:
سوپرتراشه NVIDIA GH200 Grace Hopper تراشه های بزرگ و متنوع موجود را گسترش می دهد و با اکوسیستم پردازنده های Arm 64 بیتی یعنی همان کانتینرها، باینری های کاربردی و سیستمعاملهایی که روی دیگر محصولات Arm اجرا میشوند روی Grace Hopper بدون تغییر و سریعتر اجرا میشوند و برای مشتریانی که تمایل به توسعه دارند با پشتیبانی از پلتفرم های انویدیا آن را ممکن می سازد. انویدیا دارای دو پلتفرم است NVIDIA (MG) و NVIDIA GH200 NVL32 که آن ها را بررسی خواهیم کرد:
- NVIDIA (MG): این پلتفرم با ترکیب GH200 مقیاس های شتاب دهی را کاهش می دهد و برای ML، AI، تجزیه و تحلیل داده و پایگاه های داده تحلیل دار و بارهای کاری HPC ایده آل است. این پلتفرم با ارائه 624 گیگابایت حافظه توانایی اجرای بارهای کاری متفاوت را دارد و می تواند با برخی تکنولوژی ها و راه حل های شبکه ترکیب شود و مدیریت پلتفرم را ساده سازد. این پلتفرم از معماری شبکه های خوشه ای بهره می برد.
- NVIDIA GH200 NVL32: رشته های موجود در GPI-J می توانند به دامنه NVLInk متصل شده و آن را قادر سازند که حافظه 19.5 ترابایت با پهنای باند 900 گیگابایت را در سوپر تراشه ارائه دهند و 14.4 ترابایت بر ثانیه از پهنای باند را آدرس دهی کنند. سیستم هایی که به NVLink متصل هستند از این پلتفرم برای مقیاس پذیری بالا و بارهای کاری HPC استفاده می کنند.
| Product Specifications |
|---|
| Feature GH200 GH200 NVL2 |
| CPU core count 72 Arm Neoverse V2 cores 144 Arm Neoverse V2 cores |
| L1 cache 64KB i-cache + 64KB d-cache |
| L2 cache 1MB per core |
| L3 cache 114MB 228MB |
| Base frequency | all-core single instruction, |
| multiple data (SIMD) frequency |
| 3.1GHz | 3.0GHz |
| LPDDR5X size 480GB |
| 120GB, 240GB |
| 960GB |
| 240GB, 480GB |
| Memory bandwidth Up to 384GB/s |
| Up to 512GB/s |
| Up to 768GB/s |
| Up to 1024GB/s |
| PCIe links Up to 4x PCIe x16 (Gen5) Up to 8x PCIe x16 (Gen5) |
| Feature GH200 GH200 NVL2 |
| FP64 34 teraFLOPS 68 teraFLOPS |
| FP64 Tensor Core 67 teraFLOPS 134 teraFLOPS |
| FP32 67 teraFLOPS 134 teraFLOPS |
| TF32 Tensor Core 989 teraFLOPS* | 494 teraFLOPS 1979 teraFLOPS* | 990 teraFLOPS |
| BFLOAT16 Tensor Core 1,979 teraFLOPS* | 990 teraFLOPS 3958 teraFLOPS* | 1979 teraFLOPS |
| FP16 Tensor Core 1,979 teraFLOPS* | 990 teraFLOPS 3958 teraFLOPS* | 1979 teraFLOPS |
| FP8 Tensor Core 3,958 teraFLOPS* | 1,979 teraFLOPS 7916 teraFLOPS* | 3958 teraFLOPS |
| INT8 Tensor Core 3,958 TOPS* | 1,979 TOPS 7916 TOPS* | 3958 TOPS |
| High-bandwidth memory (HBM) size 96GB HBM3 | 144GB HBM3e Up to 288GB HBM3e |
| Memory bandwidth Up to 4TB/s | Up to 4.9TB/s Up to 9.8TB/s |
| NVIDIA NVLink-C2C CPU-to-GPU |
| bandwidth |
| 900 GB/s 900 GB/s |
| Power Configurable 450 to 1000W |
| (Memory + CPU + GPU) |
| Configurable 900W to 2000W |
| (Memory + CPU + GPU) |
| Thermal solution Air cooled or liquid cooled |
| * With sparsity |
معماری NVIDIA GH200 Grace Hopper:
حافظه NVLink-C2C باعث افزایش بهره وری، توسعه و عملکرد بهتر می شود و همچنین می تواند مقدار قابل دسترسی از حافظه GPU را به رشته هایی از CPU و GPU که به صورت همزمان در حافظه CPU و GPU هستند، دسترسی آن داشته باشند. از طرفی دیگر به شما اجازه می دهد تا با تمرکز به الگوریتم ها و دسترسی به داده های مورد نیاز، کلیه صفحات انتقال داده نشود و تنها به قسمت های مورد نظر دسترسی داشته باشید.
- NVLink-C2C: این روش اتصال به صورت مستقیم است و با اتصال به پهنای باند بالا بین CPU Grace و Hopper GPI-J موجب به وجود آمدن Superchip Grace Hopper می گردد که هدف از طراحی آن شتاب دادن به AI و HPC است. این معماری با پشتیبانی از سخت افزار بومی برای عملیات اتمی مناسب است. زیرا موجب بهبود عملکرد دسترسی حافظه به حافظه غیرمحلی می شود. زمان انتظار را کاهش می دهد و عملکرد سیستم را بالا می برد و در نهایت برنامه های محاسباتی ناهمگن را با استفاده از زبان های برنامه نویسی ساده می کند.
- سیستم سوئیچ NVLink: درواقع NVIDIA NVLink Switch System ترکیبی از فناوری نسل سوم و نسل چهارم است که توانایی اتصال 32 سوپرتراشه گریس هاپر را دارد و همچنین قادر است پهنای باند کامل را در میان آن ها برقرار سازد. این معماری دارای 19.5 ترابایت حافظه است که با استفاده از MPI، NCCL و یا NVSHEMEM آدرس دهی می کند.
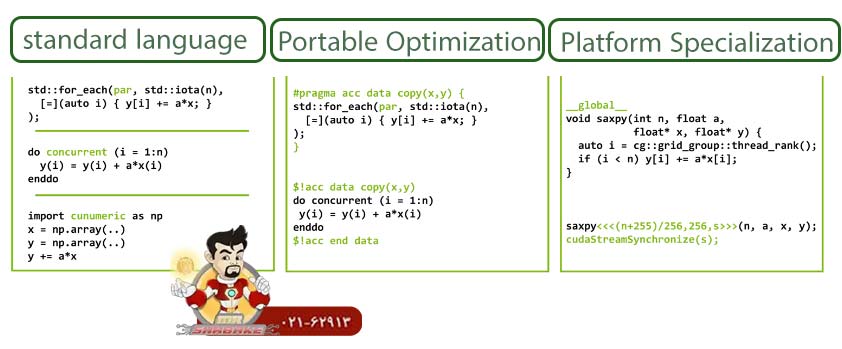
زبان های برنامه نویسی در NVIDIA GH200 Grace Hopper:
همان طور که قبلا گفتیم این پلتفرم، برنامه نویسی را ساده می سازد و زبان های برنامه نویسی که توسط این پلتفرم ارائه می شود موجب تسریع شدن استانداردها نیز می گردد.
زبان های برنامه نویسی:
- ISO Fortran
- Python
- ISO C++
مدل های برنامه نویسی:
- OpenACC
- OpenMP
- CUDA Fortran
- CUDA C++
نتیجه گیری:
کمپانی انویدیا که یکی از کمپانی های سرشناس در تولید پردازنده و کارت گرافیک است با ارائه سوپر تراشه NVIDIA GH200 Grace Hopper تحولی عظیم در دنیا به وجود آورد و از رقیبان خود Intel و AMD جلو زد. از آن جایی که امروزه هر پردازنده گرافیکی شامل هوش مصنوعی است تقاضای زیادی برای H200 وجود دارد و از آنجایی که H100 پدر H200 محسوب می شود، این محصول با قیمت مناسب و تفاوت اندک در بازار تجهیزات شبکه موجود است.
| شما میتوانید از مسترشبکه بزرگترین فروشگاه اینترنتی انواع سرور اچ پی را به همراه گارانتی خریداری نمایید. |