



همانطور که می دانید دیتا به عنوان عنصر حیاتی یک کسب و کار به حساب می آید و روزانه حجم قابل توجهی داده و اطلاعات، ایجاد، مبادله و منتقل می شود. اما تنها تعداد کمی از این دیتاهایی که در حال ایجاد و مبادله هستند، مورد استفاده قرار می گیرند و سایر دیتاها بدون استفاده بوده و بلاتکلیف باقی می مانند. حال تصور کنید که اگر دیتاها به درستی جمع آوری شده و در کنار هم قرار گیرند می تواند با کاهش خطا، شرکت و یا سازمان را به سمت موفقیت هدایت کند. ما در این مقاله سعی داریم تا شمارو با مفهوم تکنولوژی Data Fabric آشنا نماییم، پس در ادامه همراه ما باشید.
Data Fabric چیست؟
فهرست محتوا
Data Fabric یا بافت داده جدیدترین نوع طراحی دیتا است و یا به بیان دیگر پیاده سازی اصول کلی مجازی سازی دادههاست که با ارائه قابلیت های مختلف مدیریت و یکپارچه سازی دیتا، امکانات زیادی را برای مدیران کسب و کار فراهم می کند. همچنین در این روش کاربران نیز می توانند داده ها را تجزیه تحلیل و مدل سازی کنند.
به بیانی ساده تر این تکنولوژی دارایی سازمان شما که همان دیتاست را زیر ذره بین قرار داده و به جای متمرکز کردن دیتا ها در یک نقطه آن ها را به صورت پراکنده اما پیوسته به صورتی که قابل دسترسی باشد، نگهداری می کند. هدف دیتا فابریک، یکپارچه سازی دیتا برای سادهتر کردن فرآیند دسترسی برنامه به اطلاعات و همچنین، ایجاد ارتباط میان پایگاه داده و ساختار داده است. همچنین می توان از هوش مصنوعی یا AI و ماشین لرنینگ یا ML جهت فرآیند ساده سازی تحلیل استفاده کرد. در واقع این تکنولوژی در حال تبدیل شدن به یک ابزار اصلی تغییر داده های خام به هوش تجاری است.
یکی دیگر از قابلیت های دیتا فابریک، توسعه برنامه ها با ایجاد یک مدل مشترک جهت دستری آسان به اطلاعات است. که ضمن بهبود کارایی عملیاتی، امکان دسترسی راحت تر و سریع تر به اطلاعات را نیز فراهم می کند. اگر این تکنولوژی را در سطح سازمانی ببینیم، می تواند دسترسی بهتری به اطلاعات را ارائه کند.
روش عملکرد دیتافابریک چگونه است؟

اکنون میدانیم Data Fabric چیست و چه اهداف و ویژگیهایی دارد. اما پیاده سازی معماری بافت داده، مستلزم آشنایی کامل با دادههای در دسترس و پیمودن یک مسیر عملیاتی نسبتا پیچیده است. در این بخش راجع به شیوه عملکرد Data Fabric صحبت میکنیم. ابتدا باید برای اتوماسیون، ایجاد هماهنگی و مدیریت کلیه منابع با اتصال دهندهها و اجزای مشترک، طرحی تهیه کنید و نیاز به کدنویسی اختصاصی را حذف کنید.
کدها، اجزا، رابطهای اختصاصی و کاربردهای خاصی دارند، در صورتی که هدفتان ایجاد اتصال میان منابع دادههای مختلف است، باید یک وجه اشتراک ایجاد کنید. اکنون به فریم ورک دادهای نیاز دارید که امکان مدیریت دادهها را به صورت منسجم، از طریق یک منبع واحد فراهم کند و با استفاده از آن بتوانید به صورت سریع و بی وقفه به دادهها دسترسی پیدا کرده و آنها را بررسی و پردازش کنید.
برای ساختن این فریم ورک، لازم است اصول زیر را در نظر بگیرید:
- باید نسبت به دادههای در دسترس با قابلیت مشاهده و روش دسترسی به آنها، آگاهی کامل و درستی پیدا کنید.
- مجموعهای از قوانین، دستورالعملها و راهنماهای عملکردی مشترک، طراحی و ایجاد کنید، به صورتی که همه کاربران بتوانند بر اساس اصول یکسان و واحد عمل کنند.
- مسیرهای ورودی، خطوط و مسیرهای خروجی را به صورت دقیق تعریف و مدیریت کنید. همچنین، علائم و نشانههایی جهت راهنمایی افراد در نظر بگیرید.
- برای کاهش خطرات و حوادث، میتوانید از ابزارهای جدید مانند یادگیری ماشین کمک بگیرید.
بیشتر بخوانید: سرور مجازی یا VPS چیست؟ کاربرد و مزایای آن
پیاده سازی Data Fabric:
در حال حاضر یک ابزار یا پلتفرم مجزا وجود ندارد که بتوانید از آن برای ایجاد کامل معماری دیتا فابریک استفاده کنید. شما باید ترکیبی از راه حل ها را به کار بگیرید، مانند استفاده از یک ابزار مدیریت داده برتر برای اکثر نیازهای خود و سپس تکمیل معماری خود با ابزارهای دیگر و یا راه حل های کدگذاری شده سفارشی. با این حال چهار رکن وجود دارد که باید در هنگام اجرا در نظر گرفت:
- جمع آوری و تجزیه و تحلیل انواع متادیتا
- تبدیل فراداده غیرفعال به ابرداده فعال
- نمودارهای دانش را ایجاد و مدیریت کنید که داده ها را با معناشناسی غنی می کند.
- از یکپارچه سازی داده های قوی اطمینان حاصل کنید
- علاوه بر این، باید عناصر معمولی راهحل قوی یکپارچهسازی دادهها را نیز داشته باشید. این شامل مکانیسم هایی برای جمع آوری، مدیریت، ذخیره سازی و دسترسی به داده های شما می شود. به علاوه، داشتن یک چارچوب حاکمیت داده مناسب که شامل مدیریت ابرداده، اصل و نسب داده ها و بهترین شیوه های یکپارچگی داده است.
مزایای Data Fabric چیست؟
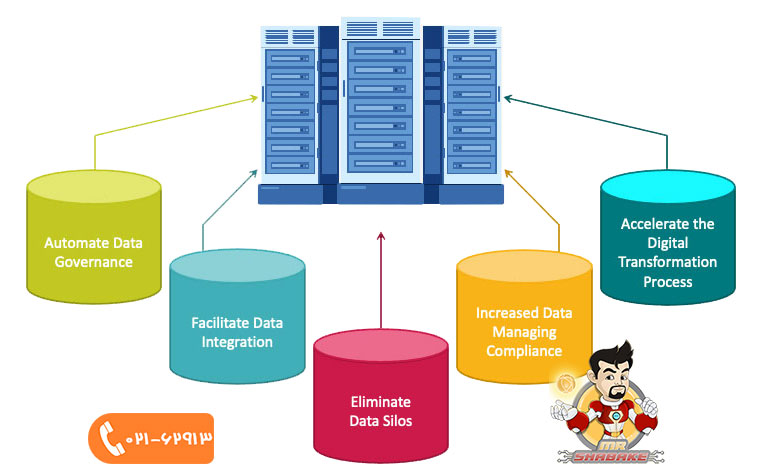
در این بخش مزایای طراحی به روش بافت داده را بررسی خواهیم کرد. این مزایا عبارت است از:
- مدیریت فرا داده:
مدیریت فرا دادهها کمی دشوار است، اما استفاده از Data Fabric، انجام این کار را سادهتر و راحتتر میکند. علاوه بر این، بافت داده امکان ایجاد ارتباط بین داده و سازمان را نیز فراهم میکند.
- بهبود کیفیت دادهها و اطلاعات:
همانطور که گفته شد عنصر اصلی و حیاتی شرکت ها و سازمان دیتا است و این دیتا باید به روز، کامل و درست باشد و همچنین بهترین عملکرد را به همراه داشته باشد. Data Fabric به کاربران امکان میدهد تا ضمن مشخص کردن کیفیت دادهها، بررسی کنند که منابع مورد استفاده برای استخراج دادهها تا چه اندازه مناسباند.
- مدلسازی دادهها:
بافت داده، قابلیت مدلسازی دادهها را نیز فراهم میکند. این قابلیت به کاربران امکان میدهد تا لایهها را ترکیب کرده و برای درک بهتر دادهها مدلی کارآمد و موثر بسازند.
- نگهداری بهتر دادهها:
با استفاده از Data Fabric، خیالتان بابت حفظ و امنیت دادهها کاملا راحت خواهد بود. همچنین، میتوانید دادهها را به صورتی نگهداری کنید که کاربران مختلف از آنها بهرهبرداری کنند.
- بدون نیاز به جابجایی داده ها:
مجازی سازی هوشمند داده ها یک نمایش واحد از داده ها از منابع متعدد و متفاوت را بدون نیاز به کپی یا جابجایی داده ها ایجاد می کند.
- مجموعه سازی دادهها:
اگر میخواهید بدانید یکی دیگر از مزایای Data Fabric چیست، باید بگوئیم به وسیله این استراتژی، میتوانید مجموعهای از دادهها را بسازید که امکان دسترسی بهتر به آنها را برای شما فراهم کند. مجموعه سازی، ضمن تفکیک دادهها از یکدیگر، دسترسی کاربران به اطلاعات را نیز آسانتر میکند.
- هماهنگی و یکپارچه سازی خودکار دادهها:
از آنجا که در سیستم طراحی بافت داده، فرآیند مدیریت و تنظیم دادهها به صورت خودکار انجام میشود، مدیریت حجم بالای دادهها آسانتر شده و هزینه و زمان تنظیم آنها نیز کاهش پیدا میکند.
- تجزیه سیلوی دادهها:
پایگاه دادههای مدرن، معمولا با گروهی از برنامهها مرتبط هستند. با اضافه شدن برنامههای کاربردی به اطلاعات موجود در سازمان، پایگاههای داده نیز تمایل به رشد پیدا میکنند. این موضوع، اغلب منجر به شکل گیری silo های داده با ساختارها و فرمتهای مختلف میشود. اینجاست که Data Fabric یا بافت داده، با توانایی توجه به طیف گستردهای از اطلاعات سازمان و استفاده از دادههای جمعآوری شده برای بهبود کارایی عملیاتی و توانمندسازی کارکنان، مطرح میشود.
- متحد کردن پایگاه دادهها:
استفاده از بافت داده، به شما اطمینان میدهد که تفاوت در موقعیت، مانعی برای دسترسی به اطلاعات ایجاد نمیکند. همچنین، توسعه برنامه را با هماهنگ کردن API های مختلف دسترسی به داده سادهتر میکند. آنها همچنین میتوانند برای بهینه سازی استفاده از دادهها و یا برای یکسان سازی دادههایی که قبلا سیلو شدهاند، مورد استفاده قرار گیرند.
تکنولوژی Data Fabric در مقابل Data Lake:
| Data Fabric | Data lake |
|---|---|
| طراحی شده برای نگهداری داده های بدون ساختار و ساخت یافته | به طور معمول داده های بدون ساختار را ذخیره کنید |
| طراحی شده برای عملیات پیچیده تر مانند یادگیری ماشین و هوش مصنوعی | معمولا برای تجزیه و تحلیل و گزارش استفاده می شود. |
| این به کاربران این امکان را میدهد تا بدون پیشپردازش دادههای منبع، به کار خود ادامه دهند. | یک فضای ذخیره سازی برای داده هایی که تمیز و فرمت شده اند فراهم کنید |
| به طور معمول در فضای ابری مستقر می شود | Data Lake را می توان در محل یا در فضای ابری مستقر کرد |
| برای اینکه مقیاس پذیرتر باشد | مقیاس پذیری کمتر |
Data Mesh در مقابل Data Fabric:
Data Mesh معماری است که در آن هدف کاهش چالش ها در زمینه موجود بودن داده ها است که به شرکت ها اجازه می دهد تا به داده های مورد نیاز خود در مکان های مختلف دسترسی داشته باشند. به طور کلی هم دیتافابریک و هم دیتامش می توانند طیف وسیعی از اهداف تجاری، فنی و سازمانی را محقق کنند اما با یکدیگر تفاوت هایی دارند. دیتافابریک ترکیبی از فناوریها از جمله هوش مصنوعی و یادگیری ماشین است به طوری که بر خلاف آن دیتا مش از تخصص متخصصان استفاده می کند. بر خلاف دیتافابریک که بر روی هوش مصنوعی و ابرداده متکی است، دیتامش بر روی ساختار، فرهنگ سازمانی و کاربرد محصولات دادهای متمرکز می باشد.
| خرید انواع تجهیزات شبکه از مسترشبکه بزرگترین فروشگاه اینترنتی تجهیزات شبکه در ایران با گارانتی معتبر |





























